Le monde du développement logiciel est en perpétuelle ébullition, cherchant sans cesse de nouvelles méthodologies pour optimiser la productivité, la qualité et la rapidité. Une approche baptisée le “Vibe Coding” peut radicalement transformer la façon de travailler dans le développement logiciel, permettant de gagner en rapidité et en efficacité comme jamais vu. Un exemple frappant et concret : le développement du site serjaq.fr. Un projet qui, sur le papier, aurait dû engloutir deux mois de travail et un budget conséquent, a été mis en orbite en à peine 50 heures.
Comment une telle compression temporelle est-elle possible ? La réponse tient en deux lettres : IA. Plus précisément, l’utilisation judicieuse et intensive des Large Language Models (LLMs) au cœur du processus de développement.
Il ne s’agira pas ici de faire l’exégèse d’une chose nébuleuse d’auto-régression linéaire sur le mot. Mais d’un retour concret, réel et le plus objectif possible, permis par une expertise de plus de 10 ans dans l’ingénierie logicielle, allant de la création de protocoles à la création de produits logiciels complets (app, API, infrastructure, interface).
Avant toute chose : qu’est-ce que donc le Vibe Coding ?
Le “Vibe Coding” est une approche de développement logiciel qui place l’intelligence artificielle au cœur du processus créatif. Contrairement aux méthodologies traditionnelles où le développeur écrit chaque ligne de code, le Vibe Coding établit une collaboration fluide entre l’humain et l’IA.
Dans cette approche, le développeur définit clairement les objectifs et les spécifications du projet, puis formule des prompts précis pour guider l’IA. Il supervise et itère rapidement sur les propositions générées, tout en se concentrant sur l’architecture globale et les décisions stratégiques qui nécessitent une expertise humaine. Son rôle évolue vers celui d’un chef d’orchestre qui valide, teste et affine le code produit par son partenaire numérique. bip bop bloup
L’IA, de son côté, prend en charge la génération du code boilerplate et des structures répétitives qui constituent souvent une part importante mais peu stimulante du travail de développement. Elle propose des implémentations basées sur les descriptions fonctionnelles fournies et traduit des concepts de design en code fonctionnel, tout en suggérant des optimisations et des alternatives techniques que le développeur pourrait ne pas avoir envisagées.
Cette symbiose permet d’atteindre une vitesse de développement inédite tout en maintenant un niveau de qualité satisfaisant. Le Vibe Coding n’est pas simplement l’utilisation ponctuelle d’outils d’IA, mais une refonte complète du workflow de développement qui maximise les forces respectives de l’humain et de la machine, créant ainsi une nouvelle dynamique où l’intuition et la créativité humaines se combinent avec la puissance de calcul et la mémoire encyclopédique bobyloniesque des LLMs dit “intelligence artificielle”.
Le défi serjaq.fr : ambition et contraintes
Avant de plonger dans le “comment”, comprenons l’ampleur de la tâche. Serjaq.fr n’est pas une simple page statique. Il s’agit d’une plateforme d’e-commerce moderne avec des exigences techniques précises :
- Un frontend réactif et performant développé avec
NextJS. - Un backend e-commerce headless robuste basé sur
Sylius. - Une solution d’analytics on-premise avec
Matomo, pour garder la main sur les données dans les serveurs. - Une chaîne d’intégration et de déploiement continus (CI/CD) avec
GitHub Actionspour automatiser les mises en production.
Traditionnellement, un tel projet mobiliserait une équipe pluridisciplinaire : designers UX/UI, développeurs frontend et backend, experts DevOps… Le coût estimé ? Aux alentours de 30 000 - 40 000 EUR. Un chiffre qui reflète les heures de conception, de développement, de tests et de déploiement nécessaires.
Mon voyage initiatique dans le Vibe Coding
Le bâton de pèlerin à la paume, l’aventure a commencé avec une exploration des outils d’assistance au développement basés sur l’IA. J’ai d’abord jeté mon dévolu sur Lovable. Cet outil m’a permis de mettre en place une première ébauche du frontend. Cependant, j’ai vite constaté que le projet généré n’était pas à jour avec les dernières versions et les meilleures pratiques de NextJS. Plutôt que de m’embourber dans des mises à niveau laborieuses, j’ai pris la décision de repartir d’une base saine en utilisant le CLI standard create-next-app.
Littéralement : l’apport de Lovable a été un échec. En l’état, ces solutions d’agents IA sont bien pour l’ébauche, mais la qualité pour de la production est discutable.
C’est à ce moment-là que le “Vibe Coding” a véritablement pris son envol. J’ai intégré Cursor, un éditeur de code conçu pour l’IA, en le couplant avec la puissance de GPT-4.1o et de Claude Sonnet 3.7. Cette combinaison s’est avérée être un catalyseur de productivité extraordinaire.
J’ai évalué le gain en temps à x3. Pas de gain en qualité cependant, au contraire la qualité produite par les LLMs implique de passer soi-même du temps d’ajustement.
L’idée du “Vibe Coding”, c’est de se mettre en phase avec l’IA, de la guider par des prompts précis, d’itérer rapidement, et de laisser le LLM se charger d’une grande partie de la génération de code, de la structuration des composants, et même de l’intégration de frameworks CSS comme TailwindCSS.
Les grands apports du Vibe Coding
L’expérience avec serjaq.fr a mis en lumière des avantages considérables :
- Une vitesse de développement stratosphérique : Passer de 2 mois à 50 heures n’est pas une simple optimisation, c’est un changement de paradigme. Les LLMs excellent dans la génération de boilerplate, l’écriture de fonctions répétitives, et la mise en place de structures de base.
- Une qualité tout à fait raisonnable : Si l’on est précis dans ses demandes et que l’on supervise le travail de l’IA, le code produit est non seulement fonctionnel mais aussi maintenable. Pour serjaq.fr, le résultat est un site fluide, moderne et qui répond aux attentes.
- Excellents designers : Une des surprises les plus agréables fut la capacité des LLMs, notamment GPT-4.1o, à interpréter des descriptions de design et à les traduire en code
TailwindCSSfonctionnel et esthétique.
Page de confirmation de commande sur serjaq.fr - Un seul prompt notifiant l’expertise en design a suffi
Un cas surprenant, un gain de temps hors norme
Un exemple particulièrement frappant de la puissance des LLMs a été leur capacité à générer du code pour Sylius, notamment pour la normalisation des attributs produits.
L’objectif était de retourner les attributs de produits avec le texte associé. Mais lorsque l’attribut est un select, par défaut Sylius retourne l’UUID de la valeur et non le texte de la valeur.
J’ai demandé au LLM de produire un code permettant de récupérer les valeurs d’attributs select en labels localisés. Voici le code généré :
| |
Pour le faire moi même avec mon niveau de connaissance de Sylius, considérant l’absence de documentation pour ce besoin, il m’aurait fallu creuser le code source de Sylius ainsi que comprendre sa structure de base de données. Cela aurait pris quelques heures, ça n’a pris que 10 minutes avec quelques prompts et contextes pour affiner.
Les “Moins” : Les écueils à ne pas ignorer
Le Vibe Coding n’est cependant pas une potion magique dénuée d’effets secondaires :
- La surveillance constante est impérative : Un LLM reste un outil. Il peut mal interpréter une demande, introduire des bugs subtils ou générer du code non optimisé. Une relecture attentive et des tests réguliers sont indispensables. Vous êtes le chef d’orchestre, l’IA est l’instrument.
- Le syndrome de la “documentation manquante” : C’est un point critique. Lorsqu’un sujet, une librairie ou une API manquent de documentation claire et accessible publiquement (sur laquelle le LLM a été entraîné), l’IA a tendance à “halluciner”. Elle invente des fonctions, des modules ou des configurations qui n’existent tout simplement pas. Ces impasses peuvent faire perdre un temps précieux si l’on ne s’en rend pas compte rapidement.
- Le spectre de la dette technique : Si l’on manque d’expertise sur une technologie ou une technique spécifique, on peut avoir du mal à guider correctement le LLM. Sans instructions précises sur les patterns à utiliser, les optimisations à prévoir ou les bonnes pratiques architecturales, l’IA peut produire du code qui fonctionnera à court terme mais qui engendrera une dette technique importante, coûteuse à résorber par la suite.
L’IA est un formidable levier, mais elle ne remplace pas l’expertise humaine. Au contraire, elle la sublime en automatisant les tâches à faible valeur ajoutée, permettant au développeur de se concentrer sur l’architecture, la logique métier complexe et la supervision.
Plus vite, mais toujours de la dette technique
Même si le Vibe Coding permet d’accélérer considérablement le développement et de gagner du temps sur la mise en œuvre de fonctionnalités, il ne préserve pas pour autant de la dette technique. En générant rapidement du code, parfois sans recul suffisant sur l’architecture ou les bonnes pratiques, on risque d’accumuler des choix techniques sous-optimaux, des solutions temporaires ou des implémentations peu maintenables. Cette dette, si elle n’est pas identifiée et traitée régulièrement, peut freiner l’évolution du projet et augmenter les coûts de maintenance à moyen et long terme.
Pour exemple :
| |
Un œil aguerri et expérimenté verrait plein de pistes d’amélioration et de problématiques amenuisant la maintenabilité de ce code. Entre autres : gestion des états transitifs standard et non-atomisée, requêtes faites avec axios quand fetch aurait fait le job, les interfaces pourraient être définies dans des typings, utilisation de any faute de contexte, etc.
L’utilisation de
zustanda été imposée par moi. Sans cela, le système aurait opté pour une approche sous-optimale, possiblement rien pour gérer les états globaux de l’app.
Un angle mort, un hack
Dès la première mise en prod la base de données a été hackée… Un angle mort induit par l’IA et pour lequel j’avais manqué de vigilance. Heureusement nous en étions qu’à la prémisse de la mise en prod, donc sans données.
La raison est simple : un port ouvert par le stack Docker du projet backend Sylius quand bien même ufw n’ouvrait que les ports nécessaires à la plublication du site. Ce port était le 3306 pour mysql. Une routine de je-ne-sais-où a trouvé le serveur, découvert ce port ouvert, a testé les accès possible à la BDD (nom d’utilisateur root et mot de passe , oui, rien), et a simplement écrasé la BDD du service.
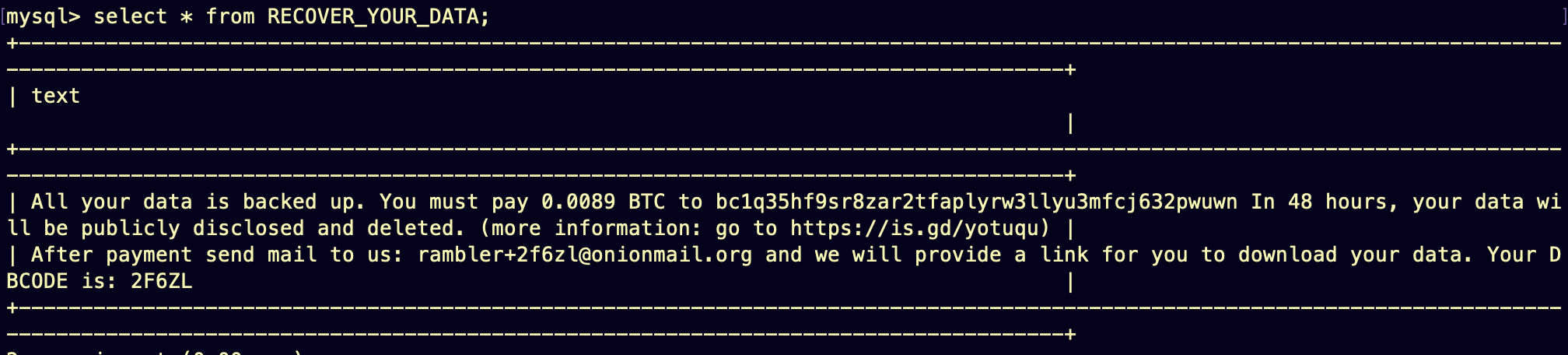
Hack de la BDD de serjaq.fr - Avec un message sympatoche
Cela est la résultante d’un manque de vigilance de ce que peut produire le LLM : ouverture du port 3306 non-nécessaire, absence d’ajout de mot de passe pour l’accès à la BDD.
Plus c’est gros, moins ça passe
Plus un projet grossit, plus le contexte se complexifie. Plus le contexte se complexifie, plus le LLM peut produire de la redondances non-nécessaire, grossissant d’avantage le projet…
Afin d’être bon, un LLM a besoin de contexte, le plus précis possible pour éviter toute hallucination. Mais cela est limité par sa capacité de “mémoire” (dits “tokens”), ça ne peut être infini, et en réalité c’est limité compte tenu de la quantité de code qu’un projet peut avoir.
Par exemple le modèle Claude 3.7 échoue à interpréter un fichier de 400 lignes
J’ai eu une discussion à ce sujet sur LinkedIn
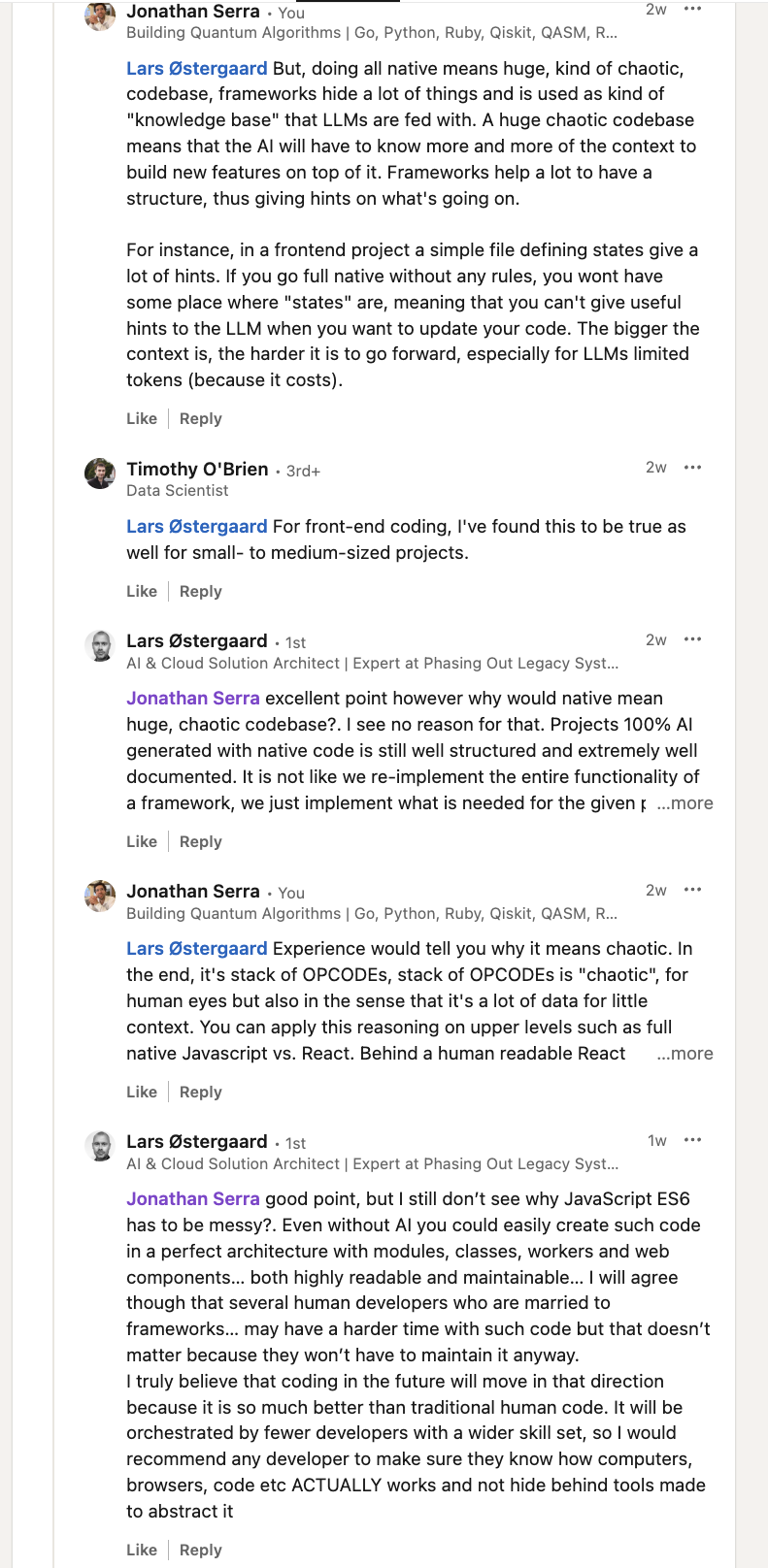
Conversation sur la génération de code avec LLM
Dans cette discussion, je souligne que le développement “full native” sans cadre structurant peut rapidement devenir chaotique, aussi bien pour les humains que pour les intelligences artificielles. Même si, en théorie, il est possible d’organiser du code natif de façon propre, la réalité montre que l’absence de conventions ou de structures imposées par un framework conduit souvent à une accumulation de code difficile à maintenir et à contextualiser. J’ai pris l’exemple du JavaScript natif face à React : derrière la lisibilité et la modularité d’un composant React, le code natif sous-jacent peut vite devenir confus, sans séparation claire des responsabilités.
Le fait que cette complexité n’est pas seulement un problème pour les développeurs humains : les LLMs, entraînés sur des données humaines, rencontrent les mêmes difficultés à comprendre et à manipuler un code peu structuré. Pour pallier ce manque de structure, on finit souvent par réinventer des frameworks ou des bibliothèques, ce qui annule l’avantage initial du “full native”.
À mesure que les LLMs progressent, ils pourraient générer leurs propres “frameworks” internes, potentiellement opaques pour les humains, ce qui risquerait de nous faire perdre la maîtrise et la compréhension du code produit et exécuté. La structuration du code reste donc essentielle, autant pour la maintenabilité humaine que pour l’efficacité de la collaboration avec l’IA.
C’est une symphonie homme-machine
Et chef d’orchestre nous pourrions devenir… L’aventure serjaq.fr est pour moi la preuve tangible que le “Vibe Coding” n’est pas un simple buzzword, mais une véritable révolution dans notre manière de concevoir et de construire des logiciels. La capacité à matérialiser une idée complexe aussi rapidement ouvre de nouvelles perspectives, notamment pour les startups, les PME ou les développeurs indépendants qui souhaitent tester rapidement des concepts sans mobiliser des ressources financières et humaines colossales.
Néanmoins, cette nouvelle ère du développement logiciel exige une vigilance accrue et une solide expertise technique. Les LLMs sont des partenaires de code surpuissants, mais ils nécessitent un pilote expérimenté pour naviguer entre les promesses d’une productivité décuplée et les récifs des hallucinations et de la dette technique. J’évoquerai ces différents sujets dans des articles à venir.
Le futur du software engineering passera sans doute par une collaboration de plus en plus étroite entre l’intelligence humaine et l’intelligence artificielle. Apprendre à “viber” avec ces nouveaux outils, c’est se donner les moyens de construire plus vite, plus intelligemment, et peut-être même, avec plus de plaisir et humilité.
Cet article a été rédigé à 90% par des LLMs. Même là ce qui devait me prendre une demi-journée m’en a demandé 2h. Cependant, les LLMs ne feront pas les pots 🏺